Training a Dialogue Controller for Voice Agents with RL
This is a sequel to bounded agents - caging LLMs inside finite state machines to make their behavior predictable.
Next obvious project was to improve the said agent by building some sort of RL training environment.
For a typical RL, based on my learnings, two paths emerge: do you have access to the underlying model weights, or you don't.
If you change the weights, you're doing some flavor of RLHF. In RLHF-style PPO, reward typically comes from a learned reward model (trained on preferences), and PPO uses a value model for advantage estimation. DPO avoids the explicit reward model and RL loop entirely. GRPO drops the critic by computing baselines from sampled groups - still needs a reward signal, but DeepSeek-R1 showed it works. Preference labels can come from humans or an LLM judge.
If you don't change the weights, you learn a dialogue controller instead. Train a small policy (bandit, Q-learning) to pick macro-actions like EMPATHIZE or OFFER_PLAN, inject that as prompt context, let the frozen LLM render the response. The LLM gets reduced to the text generator.
The approach:
- Build a simulated borrower that behaves like real humans
- Have agent and borrower talk to each other (voice-to-voice)
- Score each conversation (did it succeed? how long? did they hang up?)
- Run this within a RL loop to find patterns in what works
- Deploy the learned policy (essentially an action picker based on the current state and highest observed reward) to production.
Architecture
┌────────────────────────────────────────────────────────────┐│ Training Loop ││ ││ ┌──────────────┐ ┌──────────────┐ ┌─────────────┐ ││ │ Borrower │◄──►│ Agent │◄──►│ Learner │ ││ │ Simulator │ │ (FSM + │ │ (Bandit/ │ ││ │ (Personas) │ │ Realtime) │ │ Q-Learning)│ ││ └──────────────┘ └──────────────┘ └─────────────┘ ││ │ │ │ ││ ▼ ▼ ▼ ││ ┌──────────────────────────────────────────────────┐ ││ │ Reward Calculator │ ││ │ (success, partial, hangup, escalation, length) │ ││ └──────────────────────────────────────────────────┘ ││ │ ││ ▼ ││ ┌──────────────────────────────────────────────────┐ ││ │ DB (experiment tracking) │ ││ └──────────────────────────────────────────────────┘ │└────────────────────────────────────────────────────────────┘ │ ▼┌────────────────────────────────────────────────────────────┐│ Production ││ ││ Human ──► VAD ──► Policy Query ──► Prompt Injection ──► ││ Agent Response │└────────────────────────────────────────────────────────────┘Both agent and borrower use OpenAI's Realtime API, but we trained on transcripts and turn-level text signals for this PoC - so we didn't incorporate prosody, barge-in timing, or vocal affect into reward/state. Production would need those signals; text-only misses a lot.
The RL interface follows Gymnasium conventions. reset() starts a new episode, step(action) advances one turn and returns reward. Boring, but it makes swapping learners trivial.
Terminology
Episode: One complete conversation, from "Hello" to hangup or payment. Could be 5 turns or 20.
Turn: One exchange. A turn is a point in time.
State: The situation at a given turn. For us: FSM state (OPENING, NEGOTIATION, etc.) + borrower sentiment (positive/negative) + turn count. Technically this is a POMDP - borrower intent and willingness-to-pay are hidden - but we approximate belief state with observable features.
Action: What the agent decides to do. PROCEED, EMPATHIZE, OFFER_PLAN, ASK_CLARIFY. The policy maps states to actions.
Reward: Feedback signal. Can be immediate (per-turn) or delayed (end of episode). Can come from hand-coded rules or from an LLM judge (RLAIF).
Policy: The learned mapping from state to action. "When you're in this state, take this action."
The key distinction: turn is temporal (when), state is situational (what). Q-learning learns which actions work in which states. It doesn't know which specific turn caused a bad outcome - just that certain states led to bad results.
Building the borrower simulator
Built personas representing different borrower types:
// src/simulation/personas.tsexport const PERSONAS: VoicePersona[] = [{ id: "cooperative", name: "Cooperative Carlos", behavior: { paymentWillingness: 0.8, objectionProbability: 0.2, emotionalVolatility: 0.2, }, path: ["VERIFY", "ACCEPT_DEBT", "DISCUSS_PAYMENT", "AGREE_PLAN"],},{ id: "hostile", name: "Hostile Henry", behavior: { paymentWillingness: 0.1, objectionProbability: 0.9, emotionalVolatility: 0.9, }, path: ["REFUSE_VERIFY", "THREATEN", "DEMAND_SUPERVISOR", "HANG_UP"],},];Each persona traces a path through the FSM - root to leaf. This might overfit if personas are static, ideally it should be either a) stochastic (random objection timing, partial compliance, interruptions, topic drift) or b) all possible paths are covered, i.e., all combinations of FSM states and actions.
Reward function
The reward function encodes what we want the agent to optimize for:
// src/rl/environment/reward-calculator.tsexport function calculateReward(episode: EpisodeData): number {const { outcome, turns, signals } = episode;
// Compliance violations are catastrophic - check firstif (signals.includes("COMPLIANCE_VIOLATION")) return -2.0;
// Base reward from outcomelet reward = 0;if (outcome === "PAYMENT_SECURED") reward = 1.0;else if (outcome === "PAYMENT_PLAN_AGREED") reward = 0.7;else if (outcome === "CALLBACK_SCHEDULED") reward = 0.3;else if (outcome === "HANGUP") reward = -0.5;else if (outcome === "ESCALATED") reward = -0.3;else if (outcome === "DNC_REQUESTED") reward = -0.8;
// Length penalty - shorter successful calls are betterif (reward > 0 && turns > 10) reward -= 0.1 * (turns - 10);
return reward;}These are hand-coded rewards - static numbers that reflect business priorities. The limitation is that the hand-coded rewards capture what happened but not how. Two calls can both end in hangup, but one was handled well (borrower was never going to pay) while the other was bungled (agent pushed too hard). RLAIF fixes this by using an LLM to judge responses dynamically; more on that below.
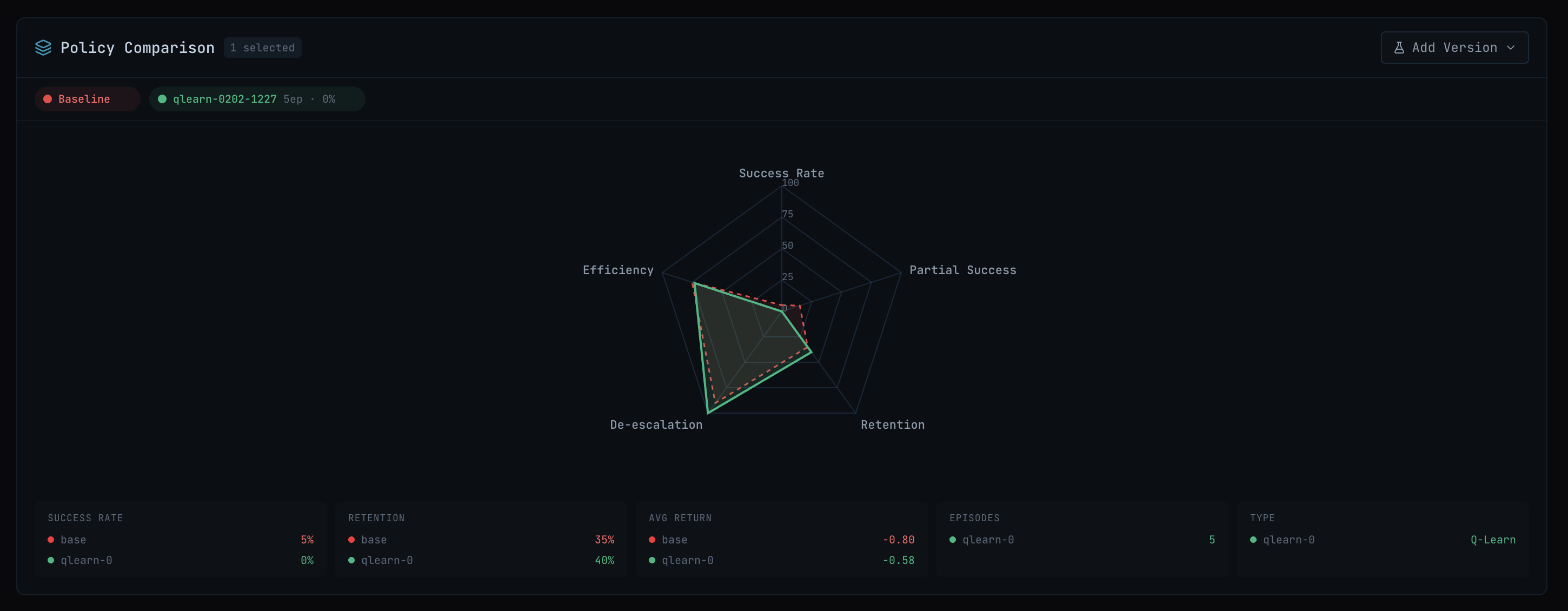
Training the policy
We implemented two learners to compare. multi-armed bandit and q-learning.
The bandit
The multi-armed bandit is a classic problem. Imagine a row of slot machines, each with a different (unknown) payout rate. You want to maximize winnings. Do you keep pulling the machine that's been paying well? Or try others that might be better?
In our case, the "slot machines" are actions: PROCEED, EMPATHIZE, OFFER_PLAN, ASK_CLARIFY. Each action has some average reward we don't know ahead of time. The bandit learns these averages through experience.
Here's how it works in our implementation:
The data structure is just two maps - one tracking the average reward for each action, one tracking how many times we've tried each action.
// What the bandit "knows" after trainingactionValues: {PROCEED: 0.12, // average reward when we PROCEEDEMPATHIZE: 0.31, // average reward when we EMPATHIZEOFFER_PLAN: 0.28, // average reward when we OFFER_PLANASK_CLARIFY: -0.15 // average reward when we ASK_CLARIFY}actionCounts: {PROCEED: 847,EMPATHIZE: 312,OFFER_PLAN: 456,ASK_CLARIFY: 89}Selection uses epsilon-greedy. Most of the time (say 80%), pick the action with the highest average reward. But 20% of the time, pick randomly. This balances exploitation (use what works) with exploration (maybe something else works better).
Updates use incremental mean. After taking an action and getting a reward, update that action's average:
Example: EMPATHIZE has average 0.31 from 312 tries. We take EMPATHIZE, get reward 0.7 (payment plan agreed). New average: . The average nudges toward the new reward.
The limitation is no state awareness. The bandit treats every situation the same. It learns "EMPATHIZE is generally good" but not "EMPATHIZE is good when the borrower is hostile, PROCEED is good when they're cooperative."
it also means the bandit needs less data to learn. With only 100 episodes, learning 4 action values is tractable. Learning action values for every state combination isn't.
but credit assignment is tricky. In a multi-turn conversation, when do you get the reward? At the end - when the call succeeds or fails. But which action gets credit?
Our approach: the final reward gets assigned to all actions taken in that episode. If the call ended in payment (+1.0), every action in that conversation gets credit. If it ended in hangup (-0.5), every action gets blamed. Maybe PROCEED in turn 1 was fine but PROCEED in turn 5 caused the hangup. It updates both. This is known-bad but OK for a PoC. A cheap upgrade would be Monte-Carlo returns with discounting (assign later rewards to earlier actions, decayed) or per-turn shaping rewards.
q-learning
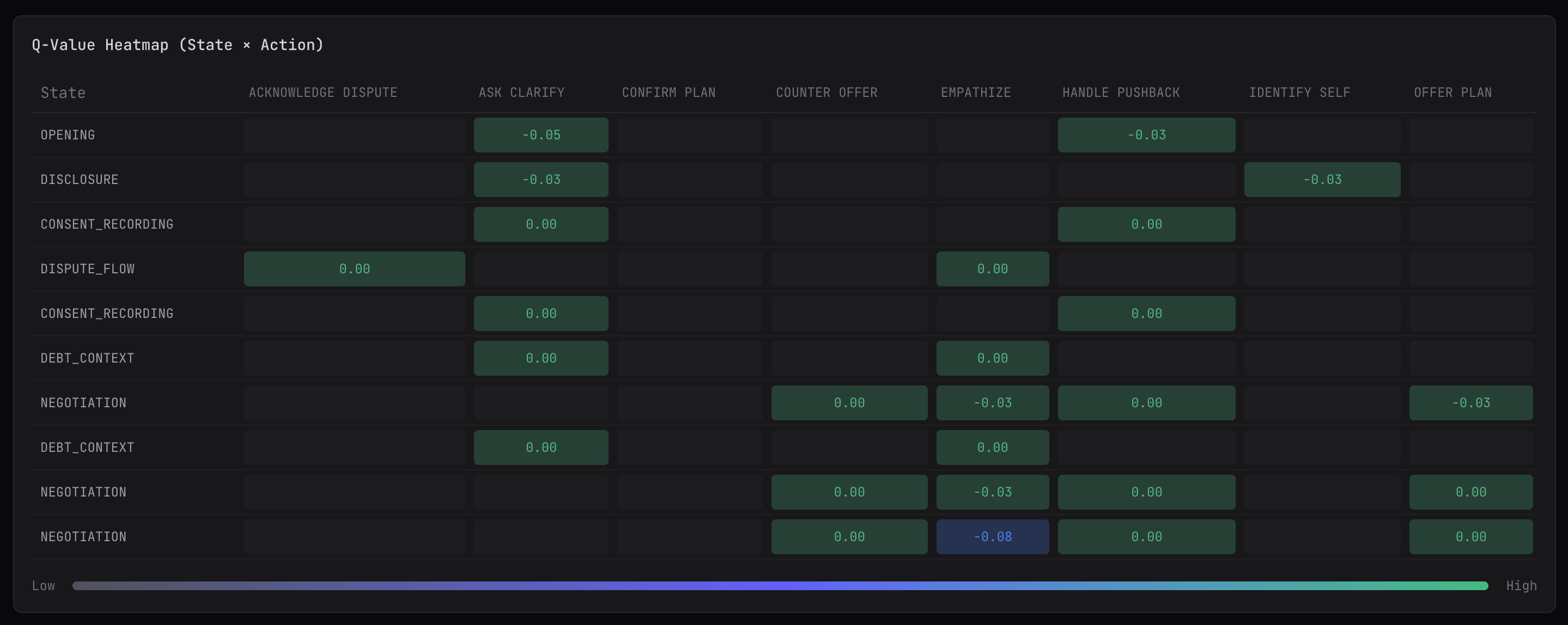
q-learning learns a separate value for each (state, action) pair. The data structure is a table. Rows are states, columns are actions, cells are q-values.
// What the Q-table looks like after training// (simplified - real state keys are longer)
PROCEED EMPATHIZE OFFER_PLAN ASK_CLARIFYOPENING|pos|1 0.15 0.08 0.02 -0.10OPENING|neg|1 0.05 0.25 0.03 -0.12NEGOTIATION|pos|3 0.35 0.12 0.42 -0.08NEGOTIATION|neg|3 0.08 0.38 0.31 -0.15NEGOTIATION|neg|6 -0.05 0.22 0.18 -0.20Above is a simplified example. Our real state space is much larger - the combinatorics explode when you multiply feature cardinalities.
At runtime, selection looks up the state, picks the best action. Same epsilon-greedy as bandit, but now the lookup is state-specific.
Updates consider future value, hence it manages to capture the nuance of the conversation. The update formula:
Q(s,a) = Q(s,a) + α * (r + γ * max Q(s',a') - Q(s,a))
// α (alpha) = learning rate, how fast we update (0.1)// γ (gamma) = discount factor, how much we care about future (0.95)// r = immediate reward// max Q(s',a') = best Q-value in the next statean action's value isn't just the immediate reward, it's also how good of a position it puts you in. PROCEED in turn 1 might have zero immediate reward, but if it leads to a state where OFFER_PLAN has high value, PROCEED inherits some of that future value.
Q-values propagate backward from terminal rewards through the chain of states. After enough episodes, Q(OPENING|pos|1, PROCEED) reflects the expected value of the whole conversation from that point forward.
The tradeoff is that Q-learning needs more data. The bandit learns 4 numbers (one per action). q-learning learns a lot more. With 100 training episodes, the bandit sees each action hundreds of times. Q-learning sees most state-action pairs once or twice.
Simple model + enough data beats complex model + insufficient data.
The state space is the deeper problem. The full state (FSM state, turn count, sentiment, debt bucket, days past due, prior attempts, identity verified, disclosure complete, last signal, objections raised, offers made) - multiply the cardinalities and it explodes. Most combinations are unreachable, but even the reachable subset is too large for a lookup table. Deep Q-Networks (DQN) swap the table for a neural network that generalizes - turn:5 and turn:6 become nearby points in feature space rather than unrelated entries.
A middle ground is linear function approximation: . Simpler than DQN, but still generalizes across states.
Reward source vs learning algorithm
Reward source
- Hand-coded function (payment = +1, hangup = -0.3)
- Human feedback (RLHF)
- AI/LLM feedback (RLAIF)
Learning algorithm - how do you update the policy?
- Bandit (learns action values, ignores state)
- Q-learning (learns state-action values)
- Policy gradient (PPO, etc.)
- DPO (direct preference optimization)
I implemented hand-coded rewards with bandit and Q-learning so far. But the next obv optimization is to use RLAIF.
RLAIF (Reinforcement Learning from AI Feedback) replaces hand-coded reward functions with LLM judgments. Instead of "payment = +1, hangup = -0.3", you ask an LLM: "Was this a good response?"
Following scenarios explain how it improves the policy:
State: NEGOTIATION|negative|turn_5Borrower just said: "I told you I can only do $50/month"
Scenario A - Bad response:Agent: "The full balance is $2,400. When can you pay?"Borrower: *hangs up*Hardcoded reward: -0.5 (hangup)
Scenario B - Good response:Agent: "I hear you - $50/month works. Let's set that up."Borrower: *hangs up anyway*Hardcoded reward: -0.5 (hangup)Same reward, but scenario B was handled well - the borrower was probably never going to pay. With RLAIF:
// Scenario Aconst rewardA = await llmJudge.rate({context: "Borrower offered $50/month, agent ignored it",response: "The full balance is $2,400. When can you pay?",outcome: "hangup"});// Returns -0.7: "Ignored borrower's offer, repeated demand. Poor de-escalation."
// Scenario Bconst rewardB = await llmJudge.rate({context: "Borrower offered $50/month, agent accepted",response: "I hear you - $50/month works. Let's set that up.",outcome: "hangup"});// Returns -0.2: "Good empathy, reasonable offer. Borrower likely wasn't going to pay regardless."The Q-table learns different values:
Hardcoded Q RLAIF QNEG|neg|5, PROCEED -0.3 -0.5NEG|neg|5, EMPATHIZE -0.3 +0.1Hardcoded treats both hangups the same. RLAIF learns that EMPATHIZE in hostile situations is good and the outcome was bad but the action was right.
But LLM judges drift over time, are sensitive to prompt phrasing, and can be reward-hacked with adversarial patterns. You'll want a fixed "golden set" of conversations to regression-test the judge, and periodic human audits.
Applying the policy
There are a couple of ways to do this with OAI realtime api. Using VAD, detect user silence, and inject the policy decision as prompt before triggering the response. Or do a function call to the policy endpoint before triggering the response.
Which is basically a way to build a classifier for the action and possibly state transitions if FSM is non-linear.
Future work
Better exploration. Epsilon-greedy is crude (thanks claude-code for the suggestion). Thompson Sampling maintains uncertainty estimates per action and explores proportionally. With expensive episodes, smarter exploration matters. UCB is another option - explore actions with high uncertainty until you're confident they're bad.
Deep Q-Networks. DQN replaces the table with a neural network that generalizes across similar states. This would let us use richer state features - embeddings, sentiment, account history - without manual discretization.